df = create_diamonds_dataframe(5, 400, .5, 1, noise_level=.025, label_by_distance=True, n_classes=4)
df.head()| x | y | |
|---|---|---|
| label | ||
| 1 | -0.257013 | 0.497711 |
| 1 | -0.210087 | 0.483057 |
| 2 | -0.255584 | 0.510315 |
| 1 | -0.201599 | 0.507479 |
| 2 | -0.236849 | 0.551901 |
create_diamonds_dataframe (n_diamonds:int=5, n_points:int=400, width:numbers.Number=1, length:numbers.Number=1, noise_level:float=0.0, label_by_distance:bool=True, n_classes:Optional[int]=5, label_key:str='label', use_index:bool=True)
create_diamonds_dataset (n_diamonds:int, n_points:int, width:numbers.Number=1, length:numbers.Number=1, noise_level:float=0.0, label_by_distance:bool=True, n_classes:Optional[int]=5)
categorize_distances (distances:NDArray[Shape['*'],Float], n_classes:int)
Categorizes distances into n_classes classes.
distance_from_origin (points:NDArray[Shape['*,[x,y]'],Float])
Calculates distance of points from the origin.
rotate_diamond (diamond:NDArray[Shape['*,[x,y]'],Float], rotation_angle:float)
Rotates a diamond by a given angle.
make_diamond (n_points:int, width:numbers.Number=1, length:numbers.Number=1)
Generates the four vertices of a diamond.
make_diamond_quadrant (n_points:int, width:numbers.Number=1, length:numbers.Number=1, is_left_half:bool=True, is_top_half:bool=True)
Generates a diamond quadrant.
Args: n_points: number of points in the quadrant is_left_half: whether the quadrant is on the left half of the diamond is_top_half: whether the quadrant is on the top half of the diamond width: width of the diamond length: length of the diamond
Returns: quadrant: the quadrant as a numpy array of shape (n_points, 2)
df = create_diamonds_dataframe(5, 400, .5, 1, noise_level=.025, label_by_distance=True, n_classes=4)
df.head()| x | y | |
|---|---|---|
| label | ||
| 1 | -0.257013 | 0.497711 |
| 1 | -0.210087 | 0.483057 |
| 2 | -0.255584 | 0.510315 |
| 1 | -0.201599 | 0.507479 |
| 2 | -0.236849 | 0.551901 |
plt.figure(figsize=(4, 4))
sns.scatterplot(data=df, x='x', y='y', hue='label', palette='Set2')
plt.show()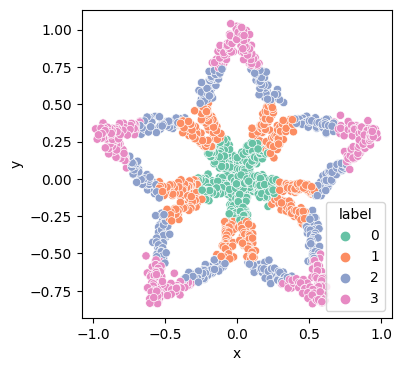
DiamondsDataset (*args, **kwargs)
dd = DiamondsDataset()
dd.getone()(tensor([[-0.1185, 0.1044],
[-0.0352, -0.2834],
[ 0.3732, 0.3249],
[ 0.5480, -0.4628],
[ 0.5855, -0.6958]]),
tensor([0., 1., 2., 3., 4.]))dd.plot(palette='mako_r')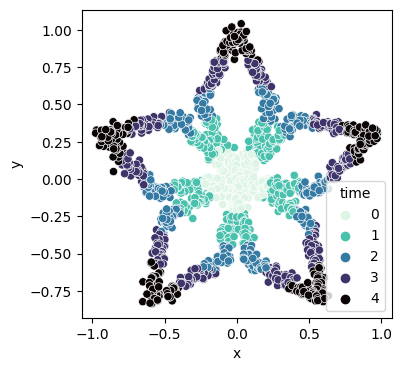
DiamondsDataModule (df:pandas.core.frame.DataFrame=<factory>, n_diamonds:int=5, n_points:int=400, width:numbers.Number=0.5, length:numbers.Number=1, noise_level:float=0.025, label_by_distance:bool=True, n_classes:Optional[int]=5, perc_train:float=0.7, perc_valid:float=0.1, perc_test:float=0.2, include_time:Optional[bool]=False, device:Optional[littyping.device.Device]=None)
ddm = DiamondsDataModule()ddm.prepare_data()DiamondsDataModule(n_diamonds=5, n_points=400, width=0.5, length=1, noise_level=0.025, label_by_distance=True, n_classes=5, perc_train=0.7, perc_valid=0.1, perc_test=0.2, include_time=False, device=None)ddm.setup()train_dl = ddm.train_dataloader()for batch in train_dl:
break
batch[0].shape, batch[1].shape(torch.Size([64, 5, 2]), torch.Size([64, 5]))len(ddm.idxs_train), len(ddm.idxs_valid), len(ddm.idxs_test)(1400, 200, 400)ddm.train_ds.df.shape(2000, 3)